


Build Confidence in Your Patch Deployments
August 15, 2022
Patching is Just Good Business
Vulnerabilities in technology are always being discovered and in response, vendors regularly issue security updates to plug the gaps. Applying these updates – a practice commonly known as patch management – closes vulnerabilities before attackers can exploit them.
Any professional involved in end-user computing or who is responsible for managing Windows environments and infrastructure is aware of the importance of patching. By the end of 2021, over 18,000 new vulnerabilities were reported with over 180,000 cumulative vulnerabilities since 1998.
Patching can also fix bugs, add new features, increase stability, and improve look and feel (or other aspects of the user experience). So patching matters for more than just security reasons. It ensures you are getting the most from your IT, and that it is working smoothly for your employees, supply chain and partners.
Cyber Attacks Elevated on a Global Scale
As the tech war between China and the U.S. heats up and the Russian Ukraine war raises the stakes, governments around the world are publishing new guidance and launching problems to combat poor cyber resilience. The US Government’s Shields Up program provides several suggestions and ensures that software is up to date, prioritizing updates that address known exploited vulnerabilities is a key strategy.
To compound matters, cybercrime is an easy business to get into because of its low cost and high returns. Attackers follow the money and concentrate on organizations that store, transmit and process high volumes of monetizable information. According to The 2022 Unit 42 Incident Response Report from Palo Alto Networks, the most targeted industries are finance, professional and legal services, manufacturing, healthcare, high tech, and wholesale and retail. In 28% of cases, having poor patch management procedures contributed to threat actors’ success.
Patch management continues to garner C-Level attention; forcing IT teams to simply move faster without disrupting the rest of the business.
Patch Velocity is Getting Slower
For all these reasons, patching remains the single most important thing you can do to secure your technology. That is why applying patches is often described as ‘doing the basics’. Although applying patches may be a simple security principle, that does not mean it is always easy to do in practice.
As software eats the world, there is no relief in sight. Consider that the average enterprise organization deploys an average of 175 applications whereas smaller companies average 73. All said that is a lot to manage for any IT operations team.
With the sheer volume, it is no surprise that the average time to apply, test and fully deploy patches is 97 days (about 3 months). The findings in the Ponemon Institute’s Third Annual Study on the State of Endpoint Security Risk reveals the difficulties in keeping endpoints effectively patched. 40% of respondents say their organizations are taking longer to test and roll out patches to avoid issues and assess the impact on performance.
VDI/DaaS Environments Mitigate Some of the Burden
VDI has been used to help organizations deploy applications and desktops using virtualization technologies from Citrix and VMware. With the recent rise in work from home initiatives, the need to rapidly deploy and support desktops and applications to a remote workforce has become business critical. VDI and newer Desktop-as-a-Service (DaaS) solutions are becoming a staple for a broader portion of the workforce.
Virtualized desktops help reduce the operational cost of patching by mitigating the delivery aspects of the process. Everything is done once, centrally and in a controlled manner. When ready, it is simply activated, ready for the next employee to connect.
That does not mean that organizations who use VDI and DaaS do not worry about patching. Remember these are complex ecosystems mixing hardware and software. The potential impact still requires testing and validation and over time creeping degradation may lead to inferior performance or inconsistent experiences.
SaaS/PaaS Creates New Challenges
Cloud computing, both SaaS and PaaS, fundamentally changes the dynamics of patching. The premise that someone else does it for you sounds great, but this model could be a troublesome issue for administrators as the vendor handles all maintenance tasks, including patching. While IT operations workload and patching responsibilities decrease significantly, the necessity to research and plan increases.
The main issue with SaaS application patching is the potential scale of any changes. Changes made to the application interface, function or APIs can affect all end users and/or disrupt integrations with other systems. With PaaS, IT organizations maintain control of the application, but not the OS or hypervisor stack. If app performance suffers post-patching, it is not as easy to blame — or change — the OS to compensate. Organizations can increase cloud instance size to improve performance, but that carries a price tag. No one should fix an issue by simply throwing more cloud resources at it.
Autopatch and Ring Based Deployment Places Pressure on End Users
Vendors continue to look for ways that minimize the burden on IT operations. Microsoft recently launched Windows Autopatch, which moves the update orchestration from organizations to Microsoft, with the burden of planning the entire process (including rollout and sequencing) no longer on IT teams.
The deployment is based on a ‘test ring’ containing a minimum number of devices, the ‘first ring’ roughly 1% of all endpoints in the corporate environment, the ‘fast ring’ around 9%, and the ‘broad ring” the rest of 90% of devices. The updates get deployed progressively, starting with the test ring, and moving on to the larger sets of devices after a validation period that allows device performance monitoring and pre-update metrics comparison.
Taking patch management out of the IT ecosystem lets valuable resources focus on other problems and optimization – it is one less drudgery to worry about. Theoretically it is a good idea, but it takes a lot of work to set up and manage all the distinct groups. Everyone becomes a patch tester and employees need to know which group they are in and how to report problems. Problems now shift the follow-up to equally resource constrained service management teams.
Risk and Complexity Hinder Progress
As you move to a mixture of on-premises, virtual, cloud and SaaS environments, the number of complex interactions between the various platforms and applications increases exponentially. To avoid downtime, IT teams must ensure that applying a patch to one system will not break the compatibility between it and any interdependent systems it must work with. That combined with the challenges of managing technical debt presents a huge problem when it comes to effective patch management.
The endless cycle of Patch Tuesday, Exploit Wednesday, and Uninstall Thursday can make even the coolest IT professional break out in a cold sweat. Everyone braces as patches are released on the second Tuesday of the month, followed by Exploit Wednesday when the cyber criminals have analyzed the details and deliver code to exploit unpatched systems. Uninstall Thursday is the day you finally figure out that it was the Tuesday patch that broke mission-critical systems, and you need to uninstall it to get things back to normal.
This is the inherent challenge – with every patch deployed comes a risk. A risk that something will break – an application that will not launch, an operating system or service that will not boot, a dramatic decrease performance, unplanned downtime, and so on.
Now enter the people equation. IT operations teams must contend with security teams, application owners, and complex change approvals that introduce effective roadblocks for a streamlined process. Application owners are required to give up some of their time to test patches, which takes time away from their releases, and business owners and teams have the same issues.
The Complicated Impact of Patching
Patch Tuesday has some recurring themes affecting core Windows features, including print services, Active Directory, and remote access services, after deploying updates. Small issues create big problems when they impact accessibility and commonly used functions. While many of these are identified quickly, some do not get discovered until after deployment – delaying other mitigation strategies.
When researchers publicized the Meltdown and Spectre flaws impacting processors, Microsoft quickly released patches that had an unintended consequence of increasing CPU utilization. The vulnerability had a much bigger effect on virtualized machines and the drop in performance significantly impacted user density and the user experience, and in limited cases required unplanned budget expenditures to compensate.
The Slowest Part of the Patch Process
Organizations have a variety of tools in their arsenal to tackle patch management – from inventory and discovery tools, distribution capabilities, validation, and compliance reporting and so on. Yet most organizations are stuck with manual processes for basic technical unit and user acceptance testing (UAT) of all patches and updates.
CSO Online says, “The conventional wisdom is that all patches should be tested across broad swathes of different types of devices and configurations before testing. Only after thorough and complete testing are patches allowed to be deployed.”
But as the scale of deployed software and updates increases, it is not feasible to test every patch. In fact, many organizations minimally test or skip the testing phase altogether. The simple fact is that the testing phase takes too long, provides unclear results, often does not reveal all problems, and may not pick up performance issues.
Understanding the impact to the overall experience post rollout relies on users to surface issues. The subsequent identification of root cause for patch failures and visibility into patches that are negatively affecting performance is not an easy task.
How to Automate the Patch Testing Gap
So how can you automate your manual steps and accelerate your patch process? Login Enterprise helps in two specific capacities: evaluate the impact in the lab first to predict patching success and then repeat after rollout to determine that critical functions have not been damaged by the patch. But more importantly, you can rely on a data driven approach that fosters confidence in the result.
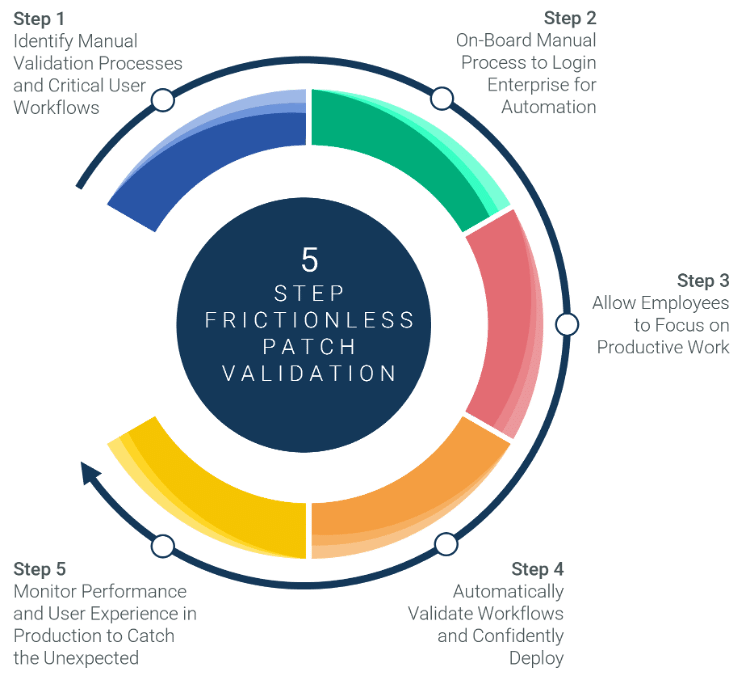
Let us walk through the five steps for frictionless patch validation.
Step 1 – Identify Manual Validation Processes and Critical User Workflows
Before you can automate your validation, you should identify the critical applications and workflows your various worker roles use daily. The goal is to replicate the main activities that impact business critical functions.
Step 2 – On-Board Manual Processes to Login Enterprise for Automation
Once identified, you can translate the manual steps an actual human would perform into step-by-step workflows that will be executed by our robotic users. This may be any combination of common activities – logging on, opening an application, and performing specific functions, and so on.
Step 3 – Allow Employees to Focus Productive Work
Using the workloads expected for each role, you can now baseline the performance and specific experience – all without extensive testing that takes employees away from their productive work. The baselines help establish your risk tolerance where performance may subtly degrade over time.
Step 4 – Automatically Validate Patches and Confidently Deploy
With every patch that requires more extensive testing, simply deploy the patch in your test environment and run the defined set of workflows. Initially, the change can be evaluated on a single instance endpoint in an isolated fashion, resulting in a rapid determination of the impact of that change only, from both an efficacy (does it work) and performance (does it impact performance) perspective. If it fails at that stage, detailed explanation.
Assuming the individual test is successful, many changes can be grouped into planned change sets that roll into production. A final validation of the integrated set can determine if the collective set of changes will impact overall efficacy and performance.
Step 5 – Proactively Monitor User Experience and Performance in Production
Finally, once changes have moved into production, you can run the same workflows from endpoints distributed around the production environment; verifying application performance and the user experience has not been impacted.
Testing Saves Time and Money, while Reducing Risk
With the steady increase in changes to be rolled into production, EUC teams run the risk of triggering application outages by failing to test the impact of these planned changes. The results can be lost revenue caused by degraded business processes, decreased customer satisfaction and reputational damage.
Automating testing changes will dramatically expand the capacity for testing, eliminating the need for manual testing – which is unpredictable and labor-intensive. The volume of bugs reintroduced into production, and the root cause analysis associated with them, will be significantly reduced. Building a robust validation model will ensure the EUC team has complete control of implementing planned changes.
Ready to Accelerate Your Patch Management Process?
If you are ready to see how Login Enterprise can help you improve your patch management process, request a demo, or contact us for more information.


